Kecerdasan buatan berkembang sangat cepat dan mulai masuk ke berbagai bidang, termasuk dunia medis. Dokter, peneliti, dan pengembang teknologi kini memiliki harapan besar bahwa model bahasa raksasa atau large language models dapat membantu memecahkan berbagai tantangan kesehatan. Model seperti ini mampu membaca, memahami, dan menghasilkan teks dalam jumlah besar dengan kecepatan luar biasa. Namun harapan besar itu tentu harus diimbangi dengan pemahaman yang jelas tentang batasan teknologi yang masih ada.
Sebuah studi terbaru dari Nature Digital Medicine memberikan gambaran menarik tentang bagaimana para ilmuwan berusaha membangun kecerdasan buatan medis yang lebih andal. Studi ini memperkenalkan dua alat penting, yaitu MedS Bench dan MedS Ins. Keduanya dirancang untuk menguji sekaligus melatih model bahasa agar lebih mampu menangani situasi klinis nyata.
Baca juga artikel tentang: Pahlawan Hijau yang Tersamar: Mengapa Sayuran Brassica Bisa Jadi Kunci Kesehatan Dunia
MedS Bench hadir sebagai langkah awal untuk menilai kemampuan berbagai model bahasa yang saat ini populer. Para peneliti menguji sembilan model yang sudah dikenal luas, mulai dari GPT hingga Llama dan Claude. Mereka menempatkan model tersebut dalam sebelas jenis tugas klinis tingkat tinggi. Tugas ini tidak sekadar menjawab pertanyaan, tetapi menguji kemampuan memahami konteks medis, menganalisis informasi kompleks, dan memberikan rekomendasi yang sesuai dengan standar klinis.
Hasil uji coba ini menunjukkan kenyataan yang perlu diakui bersama. Mayoritas model bahasa yang selama ini tampak sangat cerdas ternyata kesulitan menjalankan tugas medis yang rumit. Model mampu memberikan jawaban bagi pertanyaan umum, tetapi mulai goyah ketika konteks klinis menjadi lebih mendalam. Keputusan medis menuntut ketelitian, kemampuan menimbang risiko, dan pemahaman mendalam terhadap hubungan antar gejala, obat, dan riwayat pasien. Hal ini menunjukkan bahwa kemampuan model bahasa umum masih jauh dari standar yang dibutuhkan di ruang pemeriksaan dokter.
Kesulitan ini bukan alasan untuk berhenti. Justru melalui hasil MedS Bench, para peneliti bisa melihat celah yang harus ditutup agar kecerdasan buatan lebih siap dipakai di lingkungan kesehatan. Mereka menyimpulkan bahwa model bahasa perlu mendapat jenis pelatihan yang lebih spesifik, lebih kaya, dan lebih sesuai dengan kebutuhan klinis.
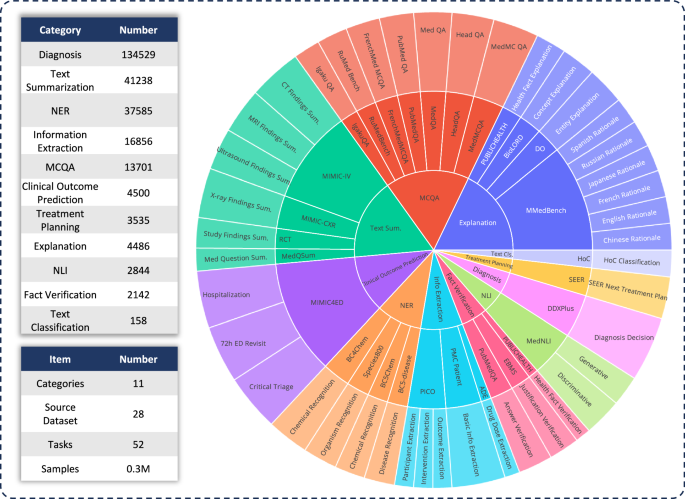
Dari sinilah MedS Ins muncul sebagai solusi. MedS Ins adalah kumpulan data instruksi medis berskala besar yang dirancang khusus untuk membantu model memahami cara berpikir dalam dunia kesehatan. Dataset ini mencakup lima puluh delapan kategori medis dengan total lima juta contoh instruksi. Peneliti tidak hanya mengumpulkan data, tetapi juga menyusunnya agar mampu mengajarkan model bahasa tentang cara memberikan jawaban yang lebih terstruktur dan klinis.
Dataset ini mencakup berbagai format pertanyaan dan situasi. Model diajak untuk belajar bagaimana dokter menilai gejala pasien, bagaimana mereka memilih diagnosis banding, bagaimana mereka menentukan obat yang sesuai, serta bagaimana mereka mempertimbangkan efek samping. Dengan tambahan data seperti ini, model bahasa mulai dilatih untuk memahami alur berpikir klinis secara menyeluruh.
Untuk membuktikan efektivitas dataset tersebut, para peneliti melakukan pengujian terhadap sebuah model bahasa sumber terbuka yang relatif ringan. Setelah dilatih menggunakan MedS Ins, model tersebut menunjukkan peningkatan kinerja yang sangat besar. Model baru yang diberi nama MMedIns Llama 3 mampu mengungguli model umum pada berbagai tugas klinis.
Ini menunjukkan bahwa kualitas kecerdasan buatan medis tidak harus bergantung pada besarnya model atau popularitasnya. Kualitas data pelatihan ternyata berperan lebih besar dalam menentukan seberapa baik model memahami dunia medis.
Selain itu, para peneliti membuka akses penuh terhadap MedS Ins bagi komunitas riset global. Mereka percaya bahwa kemajuan kecerdasan buatan medis akan lebih cepat ketika lebih banyak pihak ikut berkontribusi, memperbaiki, dan memperluas dataset tersebut. Pendekatan terbuka ini juga diharapkan dapat mendorong transparansi, sehingga perkembangan teknologi tetap berada dalam jalur yang aman dan bertanggung jawab.
Tidak hanya itu, para peneliti juga meluncurkan papan peringkat dinamis untuk MedS Bench. Papan peringkat ini menjadi alat pemantau yang memperlihatkan perkembangan setiap model bahasa dari waktu ke waktu. Model baru dapat diuji dan dibandingkan dengan model yang sudah ada, sehingga peneliti bisa melihat secara objektif mana yang benar benar siap digunakan dalam konteks medis.
Perjalanan menciptakan kecerdasan buatan medis yang aman dan andal memang tidak mudah. Model bahasa perlu mampu memahami struktur kalimat medis yang kompleks, mengenali istilah profesional, dan menghubungkannya dengan konteks klinis. Dokter dan tenaga kesehatan membutuhkan alat yang bukan hanya pintar secara teknis, tetapi juga konsisten, transparan, dan mudah diawasi.
Selain itu, kecerdasan buatan tidak boleh menggantikan penilaian seorang dokter. Teknologi hanya dapat berfungsi sebagai pendukung yang membantu meringankan beban analisis data, mempercepat proses administrasi, atau memberikan pertimbangan awal. Keputusan akhir tetap berada di tangan tenaga medis yang memahami kondisi pasien secara holistik.
Studi ini memberikan gambaran bahwa masa depan kecerdasan buatan dalam dunia kesehatan berada di jalur yang menjanjikan. Para peneliti tidak hanya berlomba menciptakan model yang semakin besar, tetapi juga semakin fokus membangun fondasi data dan evaluasi yang tepat. Inilah langkah yang sebenarnya dibutuhkan untuk memastikan teknologi dapat bekerja secara aman.
Jika model bahasa di masa depan dapat dilatih dengan dataset khusus seperti MedS Ins dan diuji secara objektif melalui MedS Bench, maka peluang untuk memiliki asisten digital klinis yang benar benar membantu semakin terbuka. Dokter bisa mendapatkan rekomendasi cepat berdasarkan bukti ilmiah, pasien bisa menerima informasi medis yang lebih akurat, dan sistem kesehatan bisa bergerak menuju layanan yang lebih efisien.
Kemajuan ini tidak datang tanpa tantangan. Transparansi model, keamanan data pasien, dan potensi bias harus terus menjadi perhatian utama. Namun dengan pendekatan penelitian yang terbuka, kolaboratif, dan berorientasi pada keselamatan, dunia medis dapat menyambut kecerdasan buatan sebagai mitra yang bisa diandalkan.
Masa depan kesehatan tampak semakin terhubung dengan teknologi. Upaya seperti MedS Bench dan MedS Ins menjadi bukti bahwa inovasi terbaik sering kali lahir ketika teknologi dan kebutuhan manusia saling menjelaskan satu sama lain. Dunia medis kini memasuki babak baru, di mana kecerdasan buatan perlahan belajar bukan hanya memahami bahasa manusia, tetapi juga merawatnya.
Baca juga artikel tentang: Kenali 8 Tanda Tubuh Mengalami Overdosis Garam yang Bisa Mengancam Kesehatan
REFERENSI:
Wu, Chaoyi dkk. 2025. Towards evaluating and building versatile large language models for medicine. npj Digital Medicine 8 (1), 58.